

一个提示,让Llama 2准确率飙至80.3%?Meta提出全新注意力机制S2A,大幅降低模型幻觉
一个提示,让Llama 2准确率飙至80.3%?Meta提出全新注意力机制S2A,大幅降低模型幻觉大语言模型「拍马屁」的问题到底要怎么解决?最近,LeCun转发了Meta发布的一篇论文,研究人员提出了新的方法,有效提升了LLM回答问题的事实性和客观性。我们一起来看一下吧。
来自主题: AI资讯
8692 点击 2023-11-28 16:00
大语言模型「拍马屁」的问题到底要怎么解决?最近,LeCun转发了Meta发布的一篇论文,研究人员提出了新的方法,有效提升了LLM回答问题的事实性和客观性。我们一起来看一下吧。
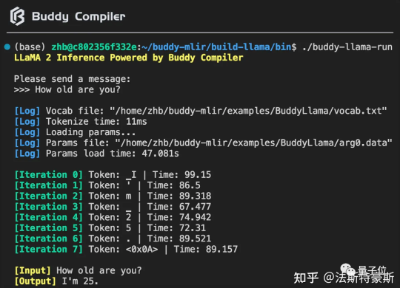
Buddy Compiler 端到端 LLaMA2-7B 推理示例已经合并到 buddy-mlir仓库[1]主线。我们在 Buddy Compiler 的前端部分实现了面向 TorchDynamo 的第三方编译器,从而结合了 MLIR 和 PyTorch 的编译生态。

RLHF今年虽然爆火,但实打实用到的模型并不多,现在还出现了替代方案,有望从开源界“出圈”;大模型透明度越来越低,透明度最高的是Llama 2,但得分也仅有54;

刚刚,英伟达发布了目前世界最强的AI芯片H200,性能较H100提升了60%到90%,还能和H100兼容。算力荒下,大科技公司们又要开始疯狂囤货了。

最近微软一项研究让Llama 2选择性失忆了,把哈利波特忘得一干二净。 现在问模型“哈利波特是谁?”,它的回答是这样婶儿的:

「AI灭绝人类」的全球讨论继续升级,Sam Altman在剑桥活动现场被抗议者当面抵制!而LeCun、吴恩达的「开源派」和Bengio、马库斯的 「毁灭派」,也纷纷甩出言辞恳切的联名信,继续征集签名中。

伦敦皇家协会举办了一场由40名科学家参与的攻克AI模型安全系统的活动,目的是发现漏洞让世人知道目前AI的技术风险
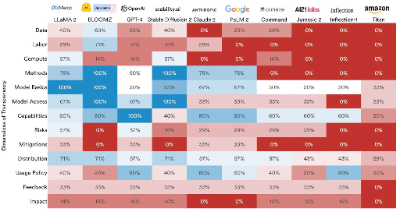
斯坦福大学的研究人员公布了一套 "基础模型透明度指数"评分系统,目的是让大家对AI模型有更深的了解

悄无声息,羊驼家族“最强版”来了! 与GPT-4持平,上下文长度达3.2万token的LLaMA 2 Long,正式登场。
就在最近,百川智能正式发布Baichuan 2系列开源大模型。作为开源领域性能最好的中文模型,在国内,Baichuan 2是要妥妥替代Llama 2了。